
Software Supply Chains: The CrowdStrike Wake-Up Call
Understanding the Systemic Cyber Risks in Today's Digital Infrastructure

Cyber outages are inevitable as software continues to eat the world, but their impact doesn't have to be catastrophic. The CrowdStrike outage affecting Windows systems this week shows how our current digital infrastructure creates huge systemic risks. This post breaks down what happened and why we need to tackle this problem head-on sooner rather than later.
Sections Covered:
Understanding the CrowdStrike Incident
The Vulnerabilities of Software Supply Chains
Navigating the Future of Cyber-Resilient Products and Systems

1. Understanding the CrowdStrike Incident
Today's products are built on complex technology stacks, comprising various programming languages, service providers, and platforms. This complexity enables advanced functionalities but also introduces significant vulnerabilities. Over 72% of the world’s desktop computers use Microsoft Windows, meaning a single flaw in such a pervasive platform can have far-reaching consequences.
CrowdStrike, the second largest cybersecurity company by market cap is known for its advanced threat detection solutions. On 19 July 2024, a faulty update to CrowdStrike's Falcon Sensor, ironically a key component of their endpoint protection product, caused many Windows systems to become inoperable and trapped in continuous restart cycles. This resulted in global business interruption across core sectors, including airlines, banks, hospitals, and emergency services with at least four thousand flights cancelled on the Friday. Falcon updates itself automatically and regularly to defend against new threats. However, this setup means that the system designed to improve security can sometimes create risks instead.

The outage underscored the substantial risks associated with B2B products deeply integrated across various industries and regions, leading to widespread disruptions in business operations and value chains. Interestingly, this incident wasn't caused by a malicious attack but by an error in a remotely deployed software update.

{kind=link}
To understand why this outage was so severe, it's crucial to understand the role of the kernel, the core part of an operating system. The kernel manages hardware resources and allows software applications to interact with the hardware. It has the highest level of access to all system resources, so any problem at this level can cause major failures. The Falcon Sensor operates at the kernel level to monitor and protect the system, so the faulty update had widespread and immediate effects.
Think of the kernel as the central nervous system of your computer. Just like your brain controls your body’s movements and responses, the kernel controls all the basic functions of your computer, like processing data and managing memory. If there’s a problem with your brain, it affects your entire body. Similarly, if there’s an issue with the kernel, it can crash the whole system, not just one application.
Consider how an application crash is like a muscle cramp. it might hurt and temporarily stop working, but the rest of your body functions normally. In contrast, a serious issue with your central nervous system, like a stroke, leads to widespread dysfunction, affecting many parts at once and complicating recovery.
The issue stemmed from outsourcing critical access to the computer’s nervous system, highlighting a significant supply chain vulnerability. Unlike incidents such as the 2021 Facebook outage, which was relatively confined to the company itself with messaging alternatives readily available, granting kernel-level access to B2B products integrated into core economic sectors can have catastrophic repercussions. When these products fail, the horizontal nature of the B2B supply chain means disruptions ripple across industries, amplifying the impact and causing widespread operational chaos.
2. The Vulnerabilities of Software Supply Chains
Modern software products carry significant third-party risks due to their reliance on numerous components, libraries, and frameworks. These layers of various technologies each have potential flaws. As technology stacks become more complex and interconnected, the likelihood of zero-day vulnerabilities increases. A zero-day vulnerability is a security flaw unknown to the vendor, giving them no time to fix it before attackers can exploit it. These vulnerabilities are particularly dangerous because they allow malicious actors to access systems before patches are available, making the management and security of all components increasingly difficult.
For example, the Log4j vulnerability, discovered in 2021 and known as Log4Shell, affected a widely used Java logging framework. This flaw allowed attackers to run any code they wanted, potentially gaining complete control of affected systems. Because Log4j is extensively used across software applications and online services, this vulnerability could be exploited easily and had a massive impact, likely affecting hundreds of millions of devices. This incident highlighted how a single vulnerability in a widely-used component can disrupt global systems.
These incidents highlight the critical importance of securing the software supply chain. As modern products depend on a complex web of interconnected technologies and third-party components, the potential risks multiply. The business model of providing mission-critical functions as a third party will likely be affected as companies become more cautious about these risks. This risk concentration extends beyond installed products to include service providers integral to your technology stack. For example, an essential API call within your product workflow can become a single point of failure. Imagine this as a truck transporting critical goods to your business. If the truck breaks down, it halts your entire supply chain, leaving your customers waiting. Similarly, if an API call fails, it can disrupt your entire software operation, leaving users unable to access crucial services and functionalities.
Moreover, these risks go beyond service interruptions to impact the security and privacy of user data. A single compromised component or service can expose sensitive information, leading to data breaches and privacy violations. This interconnected risk requires robust security measures and vigilant management of all third-party dependencies to protect both operational continuity and user data.
3. Navigating the Future of Cyber-Resilient Products and Systems
As Marc Andreessen famously wrote, Software is Eating the World. Software is becoming part of everything we do and every product we interact with, merging the physical and digital worlds. As we advance towards technologies like augmented reality (AR) and the Internet of Things (IoT), the need for strong cybersecurity becomes more critical.
While technology enhances our lives, it also introduces significant risks. It's somewhat reassuring that our critical infrastructure hasn't fully embraced IoT yet. Yes, we have smart sensors and algorithms, but the security measures to protect these technologies are often lacking.
Networking inherently introduces risk, which is why critical infrastructure such as power plants are disconnected from the network. However, for businesses and consumers, in a world where everything is becoming subscription-based and "as-a-service", we often rely on networked solutions. This means outsourcing our self-reliance to providers and being at the mercy of their supply chain and procurement choices. Moreover, many updates and changes occur in the background without our knowledge, leaving us vulnerable to unseen risks and decisions made beyond our control as illustrated in the CrowdStrike incident.
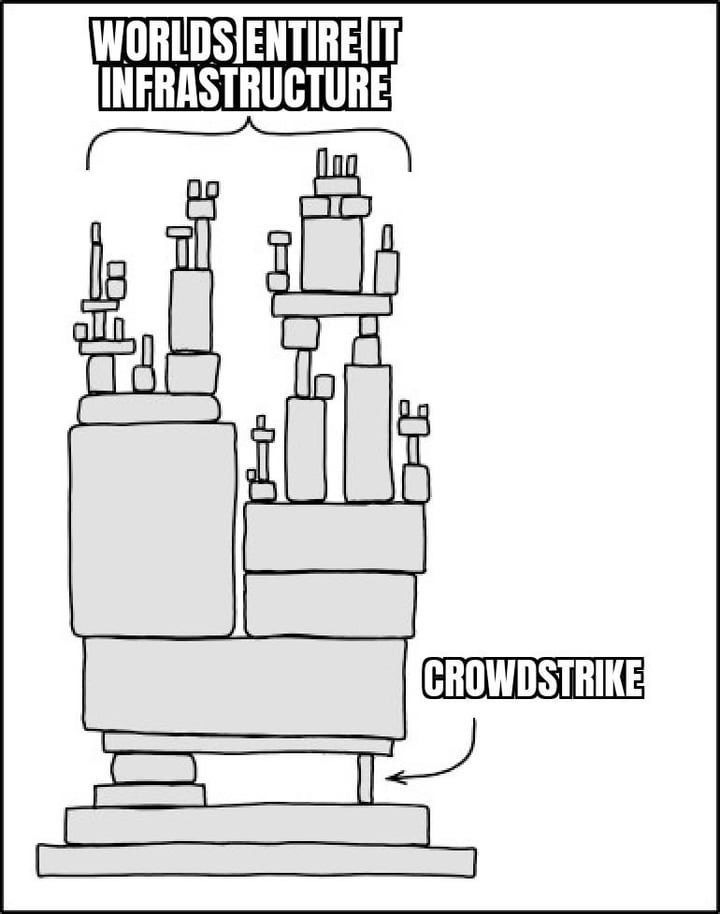
The future of secure tech products depends on several key developments. We need to design products with security in mind from the start and consider the impact of the supply chain in the services we offer. We should diversify our technological dependencies instead of relying on a few major platforms. Regulatory and industry standards will be crucial to ensuring new technologies are secure.
We’re putting the cart before the horse by constantly pushing the frontier of technology hype and using all our resources to expand the envelope of something that is decaying. We need to invest more in the reliability and maintenance of a more resilient infrastructure. Consider the amount of 'tech debt' a single company has—often, that's worrisome enough. But when you multiply this across every technology company prioritizing their go-to-market strategy to keep cash flow going, you end up with multiple hidden points of failure across the global IT infrastructure.
Stephen Moore’s post, I’m Tired of the “Next Big Thing”, captures the sentiment of hype constantly surrounding the next world-changing technology. Instead of incessantly promoting the next “world-changing” innovation, we need to prioritize practical solutions that best serve our society today. By putting the customer and user at the forefront of all design practices, we can shift our priorities to where they matter most. This means placing security, resilience, and privacy higher in the hierarchy, rather than letting our imagination chase the latest tech hype trends. Or as Gary Marcus succinctly put it — “If a single bug can take down airlines, banks, retailers, media outlets, and more, what on earth makes you think we are ready for AGI?”
It’s time to invest in the infrastructure and solutions that provide immediate, tangible benefits and build a stable foundation for the future. As we rely more on interconnected technology, our efforts to design secure systems must also increase. By learning from events like the CrowdStrike outage and giving more thought to security and resilience while designing products, we can endeavor to build a more secure technological future.
Thanks for reading!—Found value in this? Three ways to help:
Like, Comment, and Share—Help increase the reach of these ideas
Subscribe for free—Join our community of makers
Become a paid subscriber—Support this creative journey
Keep Iterating,
—Rohan

Great write up!
I used to be a mainframe developer decades ago.
I feel mainframes were a lot simpler and more robust than the present day tech stacks that’s a lot more complex.
To your point, if one update can bring down businesses across goes, something is very wrong.
My wife has been working all night for the last couple of days, and some of her clients PCs haven’t been restored yet.
What’s worse? Their entire Ops run on Azure. Azure was down too - they could not even recover their apps on the DR as that was down too!
Something is very wrong with the dependency on/monopoly of one OS and cloud in general.
They said cloud will be inexpensive and everyone started migrating. Now cloud is turning out to be more expensive than on prem with all their variable costs.
Plus, we’re 100% dependent on a third party for our business critical operations and data!